

La superioridad de los LLMs en análisis de textos, buena noticia para investigadores
Un estudio que evaluó la capacidad de los modelos de lenguaje para analizar noticias en prensa ha encontrado un nivel de "precisión sin precedentes" que supera con creces a los codificadores humanos.

A medida que la investigación en ciencias sociales y del comportamiento depende cada vez más de extraer información de grandes volúmenes de datos textuales, desde comunicados de bancos centrales hasta guiones de películas, los nuevos hallazgos indican que los grandes modelos de lenguaje (LLMs) ofrecen un método de análisis rentable que reducirá drásticamente el coste de tiempo y dinero para los investigadores.
Los autores de esta investigación —Vicente J. Bermejo (profesor adjunto en Esade), Andrés Gago y Ramiro H. Gálvez (Universidad Torcuato Di Tella) y Nicolás Harari (Universidad de Boston)— afirman que los beneficios de usar LLMs para analizar textos complejos y extensos seguirán mejorando a medida que la tecnología avance.
Hablar el idioma correcto
Los modelos de lenguaje grande (LLMs, por sus siglas en inglés) son una tecnología de aprendizaje automático que realiza tareas de procesamiento de lenguaje natural en respuesta a indicaciones proporcionadas por el usuario. Modelos populares como ChatGPT de OpenAI y Copilot de Microsoft se han vuelto habituales en escuelas y oficinas, ofreciendo respuestas instantáneas a preguntas o indicaciones específicas.
Leer y codificar contenido manualmente es un proceso costoso y que consume mucho tiempo
Los LLMs profesionales, como los modelos GPT de OpenAI y Claude de Anthropic, proporcionan un nivel más avanzado de análisis y reporte. Además, tienen la capacidad de integrar interfaces de programación de aplicaciones (APIs) para realizar tareas más complejas. A diferencia de los programas de aprendizaje supervisado (SML) que ejecutan tareas similares, como los modelos tipo BERT, las APIs no requieren conocimientos especializados de código y programación.
Herramientas de programación más simples, como Python, ofrecen una alternativa con menos necesidad de código, pero tienen una capacidad limitada. Los métodos basados en diccionarios utilizados por estos programas para analizar textos pueden contar palabras de categorías predefinidas. Sin embargo, este método limita el análisis a la categorización de contenido y, por lo general, los resultados requieren una revisión manual para garantizar su relevancia.
El humano contra la máquina
El enfoque más común para los investigadores que analizan fuentes de texto extensas es leer y codificar manualmente el contenido, un proceso costoso y que consume mucho tiempo. Para superar las múltiples barreras a las que se enfrentan los científicos sociales, cuyo análisis de registros textuales públicos es cada vez más relevante, Bermejo y sus compañeros de investigación adoptaron un enfoque novedoso.
Las tareas del estudio requerían un profundo conocimiento contextual y la capacidad de interpretar y formarse opiniones
Utilizando el amplio conjunto de LLMs disponible —específicamente, GPT-3.5-turbo, GPT-4-turbo, Claude 3 Opus y Claude 3.5 Sonnet—, pidieron a cada modelo que completara una serie de tareas cada vez más complejas usando APIs básicas. Estas mismas tareas fueron asignadas a codificadores humanos altamente capacitados. Se creó un conjunto de soluciones de referencia como punto de comparación para evaluar el desempeño tanto de los LLMs como de los codificadores humanos.
En particular, se pidió a los LLMs y a los codificadores humanos analizar 210 artículos de noticias en español relacionados con el Programa de Pago a Proveedores del Gobierno de España de 2012. Este controvertido programa, valorado en 30.000 millones de euros, fue creado para apoyar a los gobiernos locales tras la Gran Recesión de 2008-2009 y generó una amplia crítica pública.
Formando opiniones
Los investigadores establecieron cinco tareas de complejidad creciente para analizar la cobertura periodística relacionada con el programa:
- T1: Enumerar los nombres de todos los municipios mencionados en el artículo.
- T2: Indicar cuántos municipios se mencionan.
- T3: Especificar si el gobierno municipal es criticado en el artículo.
- T4: Si hay críticas, especificar quién las hace, eligiendo entre una lista de opciones.
- T5: Si hay críticas, especificar hacia quiénes están dirigidas, eligiendo entre una lista de opciones.
Estas tareas requerían tanto un profundo conocimiento contextual —por ejemplo, identificar si los artículos que mencionaban "Barcelona" se referían a la ciudad o a la provincia— como la capacidad de interpretar y formarse opiniones sobre el contenido.
Una nueva herramienta para la investigación
En todas las tareas, los modelos de lenguaje superaron a los codificadores humanos. Incluso cuando el desempeño humano fue mejor de lo esperado, los LLMs lograron resultados más precisos y consistentes.
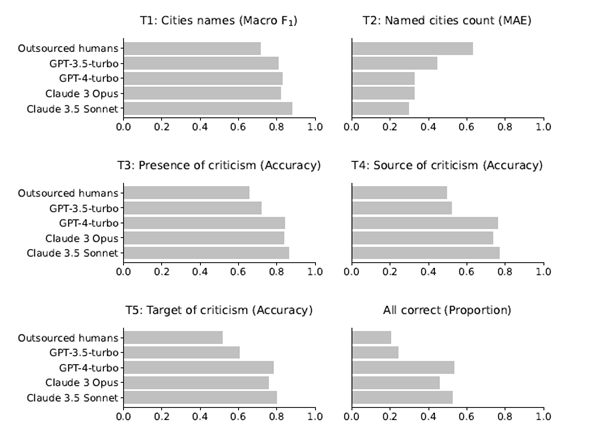
El rendimiento de los codificadores humanos y de los modelos de lenguaje se vio afectado negativamente al analizar textos difíciles o extensos, pero los LLMs mantuvieron su superioridad en todos los niveles. Incluso al comparar el análisis de artículos complejos y largos realizado por los LLMs con el análisis humano de textos cortos y simples, el desempeño de los modelos fue significativamente mejor.
Las implicaciones en términos de tiempo y costo para los investigadores e instituciones de investigación son significativas. El equipo de investigación gastó menos de 15 dólares, además de la suscripción mensual, para completar todas las tareas utilizando LLMs y resolverlas en cuestión de minutos.
Los codificadores humanos que participaron en el estudio (146 participantes) analizaron cada uno tres artículos de noticias. El tiempo medio de los humanos para completar los tres artículos fue de 17,42 minutos.
Los científicos sociales cuentan con volúmenes de datos cada vez mayores, desde publicaciones en redes sociales hasta discursos parlamentarios. Los hallazgos de la investigación de Bermejo y sus coautores sugieren que la tecnología de procesamiento de lenguaje natural (NLP, en inglés) es un recurso valioso cuyo desempeño seguirá mejorando con el tiempo.