

LLMs outperforming humans in complex text analysis is good news for researchers
A study that tested the capacity of LLMs to analyze news articles has found a level of “unprecedented accuracy” that consistently outperforms human coders.

As social and behavioral research increasingly relies on gaining insights from large volumes of text data, from central bank statements to movie scripts, new findings indicate that LLMs offer a cost-effective method of analysis that will drastically cut time and costs for researchers.
The authors of the research — Vicente J Bermejo (Assistant Professor at Esade), Andrés Gago and Ramiro H. Gálvez (Universidad Torcuato Di Tella), and Nicolás Harari (Boston University)— say the benefits of using LLMs to analyze complex and lengthy texts will continue to improve as the technology develops.
Speaking the right language
LLMs (large language models) are a machine learning technology that carries out natural language processing tasks in response to prompts given by the user. Mainstream models such as Open AI’s ChatGPT and Microsoft’s Copilot have become commonplace in schools and offices, offering instant answers to users’ questions, or prompts.
Manually reading and coding content is a costly and time-consuming process
Professional LLMs, including Open AI’s GPT models and Anthropic’s Claude, provide a more advanced level of analysis and reporting. They also have the ability to integrate application programming interfaces (APIs) to conduct more complex tasks. Unlike supervised machine learning (SML) programs that perform similar tasks, such as BERT-like models, the APIs require no specialist coding knowledge or developer skills.
Simpler programming tools, such as the commonly used Python, offer a less code-heavy alternative but are limited in capacity. The dictionary methods used by these types of programs to analyze texts can count words from pre-defined categories. However, this method limits analysis to categorizing content and the results usually require manual review to ensure relevance.
Man v machine
The most common approach for researchers analyzing lengthy text sources is to manually read and code the content — a costly and time-consuming exercise. To overcome the multiple barriers faced by social scientists, whose analysis of public text records is becoming increasingly significant, Bermejo and the research team evaluated a novel approach.
The research tasks tested required a deep contextual knowledge and the ability to interpret and form opinions
Using the widely available LLM toolset— specifically, GPT-3.5-turbo, GPT-4-turbo, Claude 3 Opus and Claude 3.5 Sonnet — they asked each model to complete a series of increasingly complex tasks using basic APIs. The same tasks were given to highly skilled human coders. A gold-standard set of correct solutions was created as a benchmark to evaluate the performance of both the LLMs and the human coders.
In particular, the LLMs and human coders were asked to analyze 210 Spanish-language news articles related to the Spanish government’s Supplier Payment Program of 2012. The controversial €30 billion program was created to support local governments following the Great Recession of 2008-2009 and attracted widespread criticism.
Forming opinions
The researchers set five tasks of increasing complexity to analyze the newspaper coverage related to the program:
- T1: List the names of all the municipalities mentioned in the article.
- T2: Indicate how many municipalities are mentioned.
- T3: Specify whether the municipal government is criticized in the article.
- T4: If there are any criticisms, specify who makes them, choosing from a list of options.
- T5: If there are any criticisms, specify towards whom they are directed, choosing from a list of options.
These tasks required both a deep contextual knowledge — identifying whether articles referring to Barcelona related to the city or the province, for example — and the ability to form opinions about the content.
A new tool in the research box
In all tasks, all the LLMs outperformed the human coders. Even when human performance was far better than expected, LLMs achieved better and more consistent results.
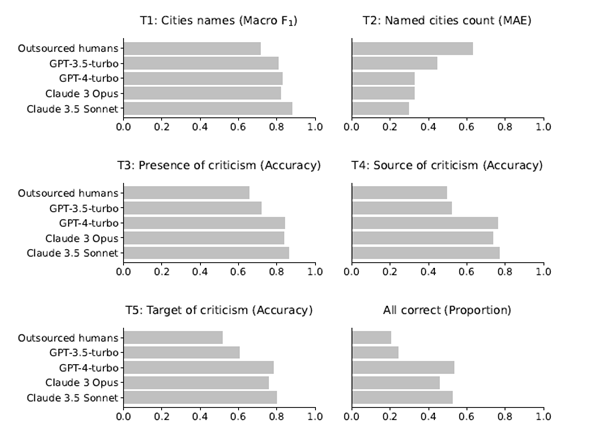
The performance of both human and LLM coders was negatively impacted when analyzing difficult or longer texts, but LLMs remained superior at all levels. Even when comparing the results of LLMs analysis of complex, lengthy articles with human analysis of short, simple texts, LLMs performance was significantly better.
The time and cost implications for researchers and research institutions are significant. The research team spent less than $15 in addition to the monthly subscription on the LLMs for all tasks — which were completed in a matter of minutes.
The human coders who took part in the study (146 participants) each analyzed three news items. The median time for humans to complete all three articles was 17.42 minutes.
Social scientists have ever-increasing volumes of data at their disposal, from social media feeds to legislative floor speeches and committee hearings. The findings of the research by Bermejo and co-authors suggest that natural language processing (NLP)technology offers a valuable resource that is only set to improve over time.