

¿Cuál es la mejor IA? El caso de Grok 3 y el problema de los benchmarks
Para decidir cuál es el mejor modelo de IA no basta con mirar las comparativas. Es necesario conocer las necesidades que tenemos y qué coste estamos dispuestos a asumir para cubrirlas.
A mediados de febrero de 2025 se presentó Grok 3, el modelo de inteligencia artificial generativa de xAI, la empresa de IA de Elon Musk, compañía que desde entonces ha lanzado ya Grok 4 (julio de 2025), repitiendo la misma estrategia. En su momento, Grok 3 fue anunciado a bombo y platillo como el mejor modelo de IA hasta el momento.
Uno de los gráficos que acompañaba a su lanzamiento así lo atestiguaba:
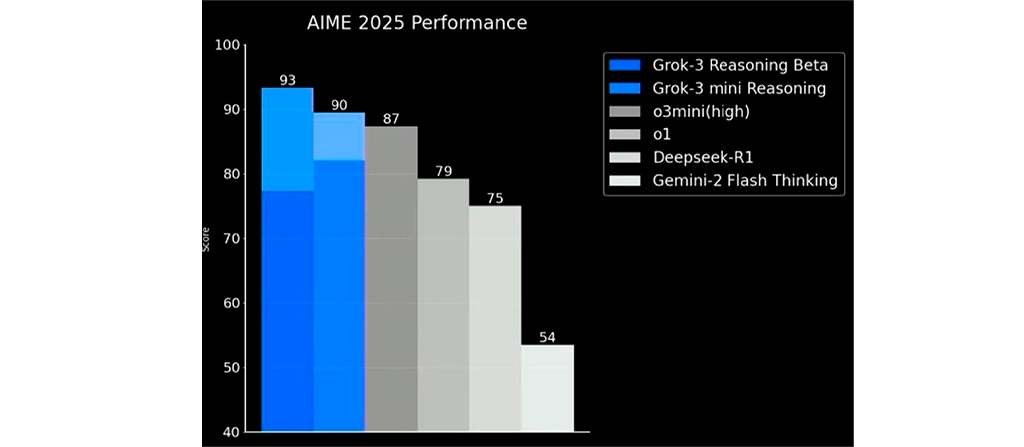
Se trata del benchmark AIME 2025, que mide los resultados obtenidos en las Olimpiadas de Matemáticas de EEUU y en el que, aparentemente, Grok 3 sobresalía sobre el resto de sus competidores.
Como se aprecia en el gráfico, el modelo xAI presentaba dos tonalidades diferentes, el único entre sus competidores. Eso se debe a que, mientras que la parte más oscura representaba su primera respuesta, la parte más clara mostraba la respuesta más común entre 64 intentos diferentes.
Solo Grok 3 incluía esta doble evaluación. ¿Por qué este criterio no es aplicado de manera uniforme en todos los modelos? En un artículo publicado en On Economía, el profesor de Esade Esteve Almirall, experto en IA e innovación, respondía: “porque así Grok 3 sale mejor en la foto”. Con un criterio unificado, el ranking quedaría así:
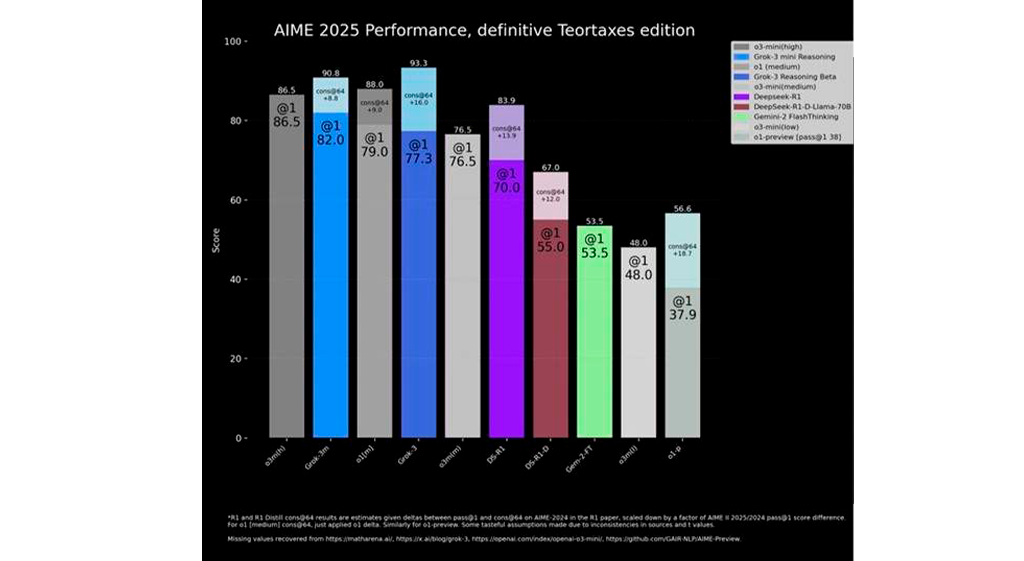
“Si solo tuviéramos en cuenta la primera respuesta, el resultado cambiaría por completo: ya no estaríamos ante el supuesto mejor modelo del mundo en matemáticas, sino ante un modelo competitivo que, a pesar de ser el más reciente, no supera a los líderes actuales”, añadía Almirall.
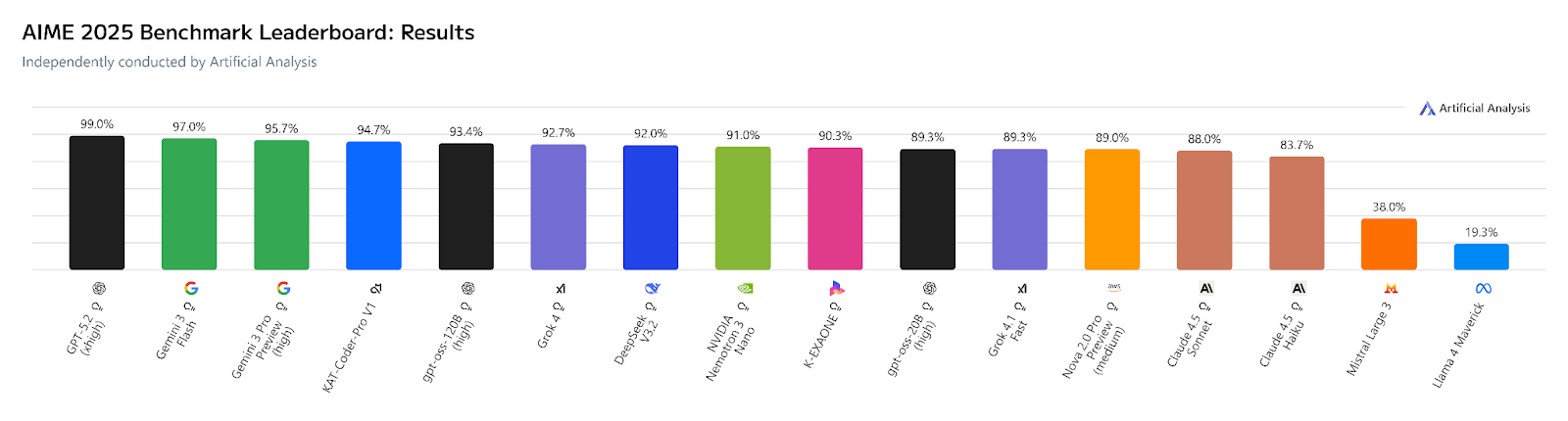
Unos meses después, ese mismo benchmark, evaluado de forma independiente por Artificial Analysis sobre 268 modelos, sitúa a GPT-5.2 en primera posición con un 99 %, seguido de Gemini 3 Flash (97 %) y Gemini 3 Pro Preview (95,7 %). El sucesor de Grok 3, Grok 4, aparece en séptima posición con un 92 %.
El problema de los benchmarks de IA
La argucia con la que xAI intentó convencer al público de que su modelo era el mejor del mundo habla de una dinámica muy presente en el sector. Los benchmarks son pruebas estandarizadas que se utilizan para evaluar y comparar el rendimiento de modelos de IA, especialmente en tareas específicas como procesamiento de lenguaje natural, visión por ordenador, razonamiento, etc.
Estas pruebas se han vuelto más sofisticadas a medida que los modelos evolucionaban, pero eso no siempre significa que los usuarios finales se beneficien de mejoras relevantes. “Pocos usuarios participan en competiciones matemáticas de alto nivel o responden exámenes de doctorado en física o biología. En cambio, la mayoría quiere que la IA traduzca bien, responda correctamente y sea comprensible”, apunta Almirall.
Algunos modelos se diseñan para maximizar puntuaciones en pruebas en lugar de mejorar la experiencia de los usuarios
Y aunque los benchmarks cumplen una función muy importante —ofrecen una forma sintética de comprender el comportamiento de un modelo—, también tienen limitaciones.
“Cuando la propia herramienta de medición se convierte en el objetivo, el resultado puede ser engañoso”, escribe el profesor. “Cada vez más modelos de IA se entrenan pensando en los benchmarks y no en los usuarios. Esto ha llevado a la aparición de términos como ‘gaming the benchmarks’ o ‘cooking the benchmarks’, que describen prácticas en las que los modelos se diseñan para maximizar puntuaciones en pruebas en lugar de mejorar la experiencia real de los usuarios”.
Esta tendencia a optimizar las métricas no es exclusiva de la IA. En el ámbito financiero se conoce como ‘contabilidad creativa’ a la práctica poco ortodoxa de manipular las cifras financieras para dar una imagen más favorable. En algunos países, las estadísticas infladas para cumplir objetivos políticos han acuñado el término ‘fake GDP’. Y otro ejemplo ilustre es el de la ‘cocina’ de las encuestas electorales para favorecer a unos candidatos u otros.
¿Y qué ocurre con lo que no se mide?
Más allá de sus limitaciones técnicas, los benchmarks también suelen ignorar una dimensión cada vez más relevante en el desarrollo de la inteligencia artificial: la eficiencia.
En la carrera por obtener los mejores resultados en métricas estandarizadas, muchos modelos se construyen bajo la lógica del bigger is better, buscando aumentar la potencia a base de dedicar más recursos y capacidad de computación. Pero esta aproximación genera dudas sobre su sostenibilidad, tanto desde el punto de vista ambiental como el económico.
Como toda industria, la IA tendría debe someterse a controles de calidad, criterios de impacto y evaluaciones de eficiencia
El consumo de recursos necesario para entrenar y hacer funcionar los grandes modelos de lenguaje (LLMs) como Grok 3 o Chat GPT ha crecido de forma exponencial, mientras que las mejoras en su rendimiento son cada vez más marginales. Y en todo caso, los sistemas de evaluación actuales no miden cuánta agua, energía o materiales se necesitan para obtener una determinada puntuación. Para la profesora Irene Unceta, directora académica del Grado en Negocios e Inteligencia Artificial de Esade, “la industria de la IA, como cualquier otra, tendría que estar sometida a controles de calidad, criterios de impacto y evaluaciones de eficiencia”.
¿Cuál es la mejor IA? Más allá de los rankings
Pese a todo, hay algunos motivos para la esperanza. El último modelo de DeepSeek, desarrollado en China bajo importantes restricciones logísticas, anuncia la posibilidad de un cambio de paradigma. Su irrupción ha demostrado que es posible —y deseable— alcanzar resultados competitivos con un uso de recursos mucho más eficiente.
Determinar cuál es la mejor IA actualmente exige, por tanto, ir más allá del benchmark de IA. Implica preguntarse: ¿Mejor para qué tarea? ¿Mejor para qué usuario? ¿Mejor bajo qué restricciones de coste, privacidad o consumo energético? No existe una respuesta universal porque la idoneidad de un modelo depende directamente del contexto en el que se aplica. Lo que implica conocer cuáles son las necesidades que tenemos como individuos y como sociedad, y qué coste estamos dispuestos a asumir para cubrirlas.
¿Qué criterios tener en cuenta al evaluar un modelo de IA?
Ante la proliferación de herramientas y la dificultad de comparar los benchmarks de modelos de IA de forma objetiva, conviene tener en cuenta los siguientes criterios a la hora de evaluar qué modelo se adapta mejor a cada necesidad:
- Adecuación a la tarea concreta: no todos los modelos son igualmente competentes en traducción, análisis de datos, generación de código o razonamiento complejo.
- Coste de uso y accesibilidad: el precio por consulta o por API puede ser determinante para individuos, pymes o investigadores con presupuesto limitado.
- Eficiencia energética y huella ambiental: un criterio ausente en la mayoría de los benchmarks de IA, pero crecientemente relevante desde perspectivas regulatorias y corporativas.
- Transparencia y gobernanza: el grado de apertura del modelo, la disponibilidad de documentación y las políticas de uso responsable también forman parte de una evaluación integral.