

Which is the best AI? The case of Grok 3 and the benchmark problem
To determine which AI model is the best, it’s not enough to look at benchmarks. It’s essential to understand our needs and the cost we’re willing to bear to meet them.
In mid-February 2025, Grok 3, the generative artificial intelligence model from xAI, Elon Musk's AI company, was unveiled. The company has since launched Grok 4 (July 2025), repeating the same strategy. At the time, Grok 3 was announced with great fanfare as the best AI model to date.
One of the graphics accompanying its launch attested to this:

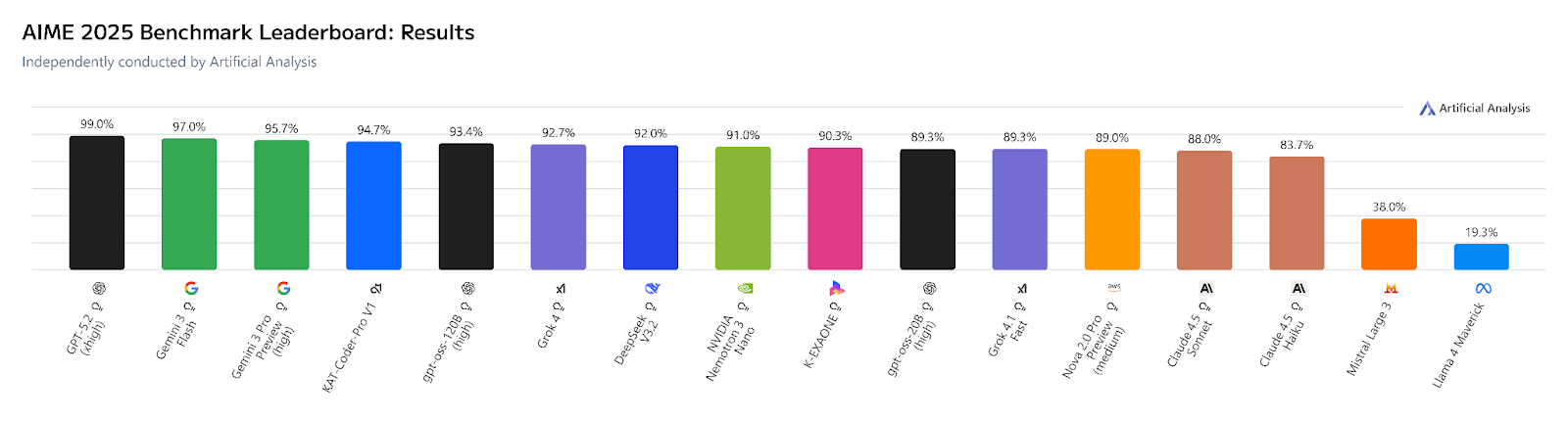
This is the AIME 2025 benchmark, which measures results obtained in the US Mathematics Olympiad and in which Grok 3 apparently outperformed all of its competitors.
In the graph below, we can see that Grok stood out from the rest of its competitors. However, the xAI model is the only one that had two shades in the graph. This is because, while the darker part represented its first response, the lighter part showed the most common response among 64 different attempts.
No other model was evaluated under this dual criterion. Why? As Esteve Almirall, professor at Esade and expert in AI and innovation, explained in the Spanish outlet On Economía: "Because that way Grok 3 looks better in the picture." With a standardized, single-response criterion applied to all models, the ranking looked quite different:

“If we only considered the first response, the result would be completely different: we would no longer be looking at the supposed best math model in the world, but rather a competitive one that, despite being the most recent, doesn’t outperform current leaders,” Almirall added.
A few months later, that same benchmark, independently evaluated by Artificial Analysis on 268 models, ranks GPT-5.2 in first place with 99%, followed by Gemini 3 Flash (97%) and Gemini 3 Pro Preview (95.7%). Grok 3's successor, Grok 4, appears in seventh place with 92%
Why AI benchmarks don't tell you which is the best AI model
The little trick xAI used to convince the public that its model was the best in the world reflects a widespread dynamic in the industry. In the AI sector, benchmarks are standardized tests used to assess and compare the performance of new models, especially in specific tasks such as natural language processing, computer vision, reasoning, and more.
These tests are becoming more sophisticated as models evolve, but that doesn’t always mean end users benefit from relevant improvements. “Few users participate in high-level math competitions or answer doctoral-level physics or biology exams. Most people want AI to translate accurately, respond correctly, and be easy to understand,” Almirall noted.
Some models are designed to maximize scores on tests instead of improving the user experience
And while benchmarks serve an important purpose—they offer a synthetic way to understand a model’s behavior—they also have limitations.
“When the measurement tool itself becomes the goal, the outcome can be misleading,” the professor wrote. “More and more AI models are trained with benchmarks in mind, not users. This has led to the emergence of terms like ‘gaming the benchmarks’ or ‘cooking the benchmarks,’ which refer to practices where models are designed to maximize test scores instead of improving the actual user experience.”
This tendency to optimize metrics is not exclusive to AI. In finance, the unorthodox practice of manipulating numbers to present a more favorable picture is known as ‘creative accounting.’ In some countries, inflated statistics used to meet political targets have led to the term ‘fake GDP.’ And a well-known example is the ‘cooking’ of electoral polls to benefit certain candidates.
What AI benchmarks don't measure: Energy, cost, and real-world performance
Beyond their technical limitations, benchmarks also tend to overlook a dimension that’s becoming increasingly relevant in AI development: efficiency.
In the race to achieve top results on standardized metrics, many models are built under a “bigger is better” logic, aiming to boost performance by using more resources and computing power. But this approach raises questions about their sustainability—both environmental and economic.
Like any industry, AI should be subject to quality controls, impact criteria, and efficiency evaluations
The resource consumption required to train and run large language models (LLMs) like Grok 3 or ChatGPT has grown exponentially, while performance gains are increasingly marginal. And in any case, current evaluation systems don’t measure how much water, energy, or materials are needed to achieve a given score. For Professor Irene Unceta, academic director of the Bachelor’s Degree in Business and Artificial Intelligence at Esade, “the AI industry, like any other, should be subject to quality controls, impact criteria, and efficiency assessments.”
What is the best AI? Beyond the rankings
Nevertheless, there are some reasons for hope. The latest model from DeepSeek, developed in China under significant logistical constraints, signals the potential for a paradigm shift. Its emergence has shown that it is possible—and desirable—to achieve competitive results with far more efficient use of resources.
Determining which is currently the best AI therefore requires going beyond the AI benchmark. It involves asking: best for which task? Best for which user? Best under what cost, privacy or energy consumption constraints? There is no universal answer because the suitability of a model depends directly on the context in which it is applied. This means understanding what our needs are as individuals and as a society, and what cost we are willing to bear to meet them.
Answering the question of which is the best AI, therefore, is not just about looking at benchmarks. It means understanding what our needs are as individuals and as a society, and what cost we’re willing to accept to meet them.
What criteria should be considered when evaluating the best AI model?
Given the proliferation of tools and the difficulty of objectively comparing AI model benchmarks, the following criteria should be considered when evaluating which model best suits each need:
- Task suitability: Not all models perform equally well across translation, data analysis, code generation, or complex reasoning. Match the tool to the job.
- Cost and accessibility: Price per query or API call can be a decisive factor for individuals, SMEs, or researchers with limited budgets.
- Energy efficiency and environmental footprint: Largely absent from most AI benchmarks, but increasingly relevant from both a regulatory and corporate responsibility standpoint.
- Transparency and governance: A model's openness, the availability of its documentation, and its responsible use policies are all part of any thorough evaluation.
The question of what is the best AI isn't answered by a leaderboard. It's answered by understanding what you need and what you're willing to pay, in every sense of the word, to get it.